publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
- ICLR
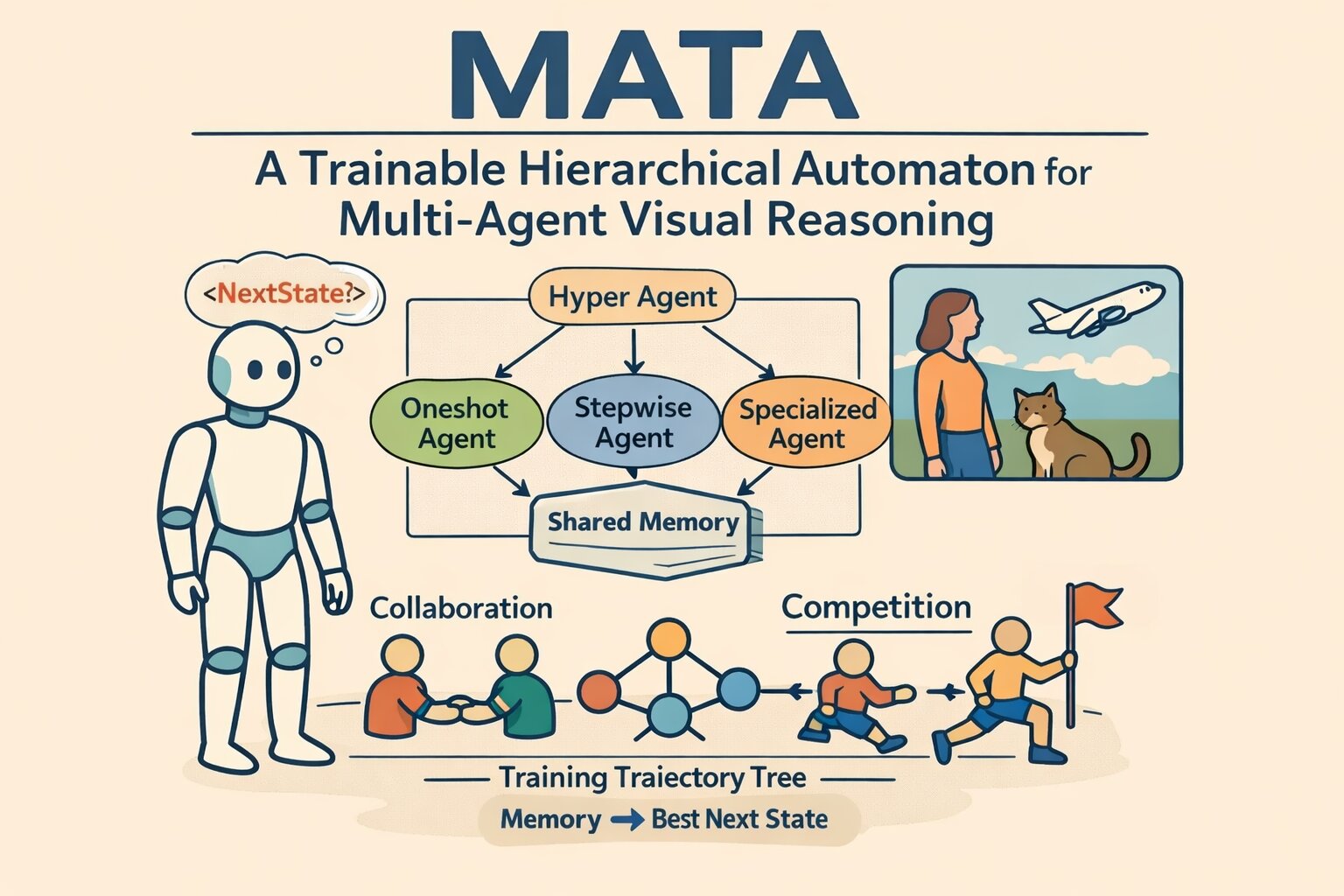 MATA: A Trainable Hierarchical Automaton System for Multi-Agent Visual ReasoningZhixi Cai, Fucai Ke, Kevin Leo, Sukai Huang, Maria Garcia de la Banda, Peter J Stuckey, and Hamid RezatofighiIn International Conference on Learning Representations , 2026
MATA: A Trainable Hierarchical Automaton System for Multi-Agent Visual ReasoningZhixi Cai, Fucai Ke, Kevin Leo, Sukai Huang, Maria Garcia de la Banda, Peter J Stuckey, and Hamid RezatofighiIn International Conference on Learning Representations , 2026Recent vision-language models have strong perceptual ability but their implicit reasoning is hard to explain and easily generates hallucinations on complex queries. Compositional methods improve interpretability, but most rely on a single agent or hand-crafted pipeline and cannot decide when to collaborate across complementary agents or compete among overlapping ones. We introduce MATA (Multi-Agent hierarchical Trainable Automaton), a multi-agent system presented as a hierarchical finite-state automaton for visual reasoning whose top-level transitions are chosen by a trainable hyper agent. Each agent corresponds to a state in the hyper automaton, and runs a small rule-based sub-automaton for reliable micro-control. All agents read and write a shared memory, yielding transparent execution history. To supervise the hyper agent’s transition policy, we build transition-trajectory trees and transform to memory-to-next-state pairs, forming the MATA-SFT-90K dataset for supervised finetuning (SFT). The finetuned LLM as the transition policy understands the query and the capacity of agents, and it can efficiently choose the optimal agent to solve the task. Across multiple visual reasoning benchmarks, MATA achieves the state-of-the-art results compared with monolithic and compositional baselines. The code and dataset are available at https://github.com/ControlNet/MATA.
- VIEW2SPACE: Studying Multi-View Visual Reasoning from Sparse ObservationsFucai Ke , Zhixi Cai, Boying Li, Long Chen, Beibei Lin, Weiqing Wang, Pari Delir Haghighi, Gholamreza Haffari, and Hamid RezatofighiarXiv preprint arXiv:2603.16506, 2026
Multi-view visual reasoning is essential for intelligent systems that must understand complex environments from sparse and discrete viewpoints, yet existing research has largely focused on single-image or temporally dense video settings. In real-world scenarios, reasoning across views requires integrating partial observations without explicit guidance, while collecting large-scale multi-view data with accurate geometric and semantic annotations remains challenging. To address this gap, we leverage physically grounded simulation to construct diverse, high-fidelity 3D scenes with precise per-view metadata, enabling scalable data generation that remains transferable to real-world settings. Based on this engine, we introduce VIEW2SPACE, a multi-dimensional benchmark for sparse multi-view reasoning, together with a scalable, disjoint training split supporting millions of grounded question-answer pairs. Using this benchmark, a comprehensive evaluation of state-of-the-art vision-language and spatial models reveals that multi-view reasoning remains largely unsolved, with most models performing only marginally above random guessing. We further investigate whether training can bridge this gap. Our proposed Grounded Chain-of-Thought with Visual Evidence substantially improves performance under moderate difficulty, and generalizes to real-world data, outperforming existing approaches in cross-dataset evaluation. We further conduct difficulty-aware scaling analyses across model size, data scale, reasoning depth, and visibility constraints, indicating that while geometric perception can benefit from scaling under sufficient visibility, deep compositional reasoning across sparse views remains a fundamental challenge.
- JRDB-Reasoning: A Difficulty-Graded Benchmark for Visual Reasoning in RoboticsSimindokht Jahangard, Mehrzad Mohammadi, Yi Shen , Zhixi Cai, and Hamid RezatofighiIn Proceedings of the AAAI Conference on Artificial Intelligence , 2026
Recent advances in Vision-Language Models (VLMs) and large language models (LLMs) have greatly enhanced visual reasoning, a key capability for embodied AI agents like robots. However, existing visual reasoning benchmarks often suffer from several limitations: they lack a clear definition of reasoning complexity, offer have no control to generate questions over varying difficulty and task customization, and fail to provide structured, step-by-step reasoning annotations (workflows). To bridge these gaps, we formalize reasoning complexity, introduce an adaptive query engine that generates customizable questions of varying complexity with detailed intermediate annotations, and extend the JRDB dataset with human-object interaction and geometric relationship annotations to create JRDB-Reasoning, a benchmark tailored for visual reasoning in human-crowded environments. Our engine and benchmark enable fine-grained evaluation of visual reasoning frameworks and dynamic assessment of visual-language models across reasoning levels.
- Mini-BEHAVIOR-Gran: Revealing U-Shaped Effects of Instruction Granularity on Language-Guided Embodied AgentsSukai Huang, Chenyuan Zhang, Fucai Ke , Zhixi Cai, Gholamreza Haffari, Lizhen Qu, and Hamid RezatofighiarXiv preprint arXiv:2604.17019, 2026
Instruction granularity is an important yet poorly controlled variable in language-guided embodied AI. Existing benchmarks typically pair each task with a single static instruction, making it difficult to study how agent behavior changes when the same task is described at different levels of detail. We introduce Mini-BEHAVIOR-Gran, a new benchmark for controlled studies of instruction granularity that extends Mini-BEHAVIOR with multiple instruction variants per task, ranging from high-level goal descriptions to step-by-step guidance. Using this benchmark, we compare four candidate metrics for cross-task granularity quantification: token count, entity count, action-verb count, and planning-width, and find that width correlates most consistently with agent performance. Using width to organize training and evaluation further reveals a non-monotonic U-shaped relationship between instruction granularity and performance, with peaks at both fine and coarse extremes. Further analysis suggests that the coarse-granularity performance rebound is associated with shallow grounding, where agents learn vision-dominant policies.



2025
- NAVER: A Neuro-Symbolic Compositional Automaton for Visual Grounding with Explicit Logic ReasoningZhixi Cai, Fucai Ke, Simindokht Jahangard, Maria Garcia de la Banda, Reza Haffari, Peter J. Stuckey, and Hamid RezatofighiIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , 2025
Visual Grounding (VG) tasks, such as referring expression detection and segmentation tasks are important for linking visual entities to context, especially in complex reasoning tasks that require detailed query interpretation. This paper explores VG beyond basic perception, highlighting challenges for methods that require reasoning like human cognition. Recent advances in large language methods (LLMs) and Vision-Language methods (VLMs) have improved abilities for visual comprehension, contextual understanding, and reasoning. These methods are mainly split into end-to-end and compositional methods, with the latter offering more flexibility. Compositional approaches that integrate LLMs and foundation models show promising performance but still struggle with complex reasoning with language-based logical representations. To address these limitations, we propose NAVER, a compositional visual grounding method that integrates explicit probabilistic logic reasoning within a finite-state automaton, equipped with a self-correcting mechanism. This design improves robustness and interpretability in inference through explicit logic reasoning. Our results show that NAVER achieves SoTA performance comparing to recent end-to-end and compositional baselines.
- NEUSIS: A Compositional Neuro-Symbolic Framework for Autonomous Perception, Reasoning, and Planning in Complex UAV Search MissionsZhixi Cai*‡, Cristian Rojas Cardenas*, Kevin Leo*, Chenyuan Zhang*, Kal Backman* , Hanbing Li*, Boying Li, Mahsa Ghorbanali, Stavya Datta, Lizhen Qu , and 7 more authorsIEEE Robotics and Automation Letters, 2025
This paper addresses the problem of autonomous UAV search missions, where a UAV must locate specific Entities of Interest (EOIs) within a time limit, based on brief descriptions in large, hazard-prone environments with keep-out zones. The UAV must perceive, reason, and make decisions with limited and uncertain information. We propose NEUSIS, a compositional neuro-symbolic system designed for interpretable UAV search and navigation in realistic scenarios. NEUSIS integrates neuro-symbolic visual perception, reasoning, and grounding (GRiD) to process raw sensory inputs, maintains a probabilistic world model for environment representation, and uses a hierarchical planning component (SNaC) for efficient path planning. Experimental results from simulated urban search missions using AirSim and Unreal Engine show that NEUSIS outperforms a state-of-the-art (SOTA) vision-language model and a SOTA search planning model in success rate, search efficiency, and 3D localization. These results demonstrate the effectiveness of our compositional neuro-symbolic approach in handling complex, real-world scenarios, making it a promising solution for autonomous UAV systems in search missions.
- AV-Deepfake1M++: A Large-Scale Audio-Visual Deepfake Benchmark with Real-World PerturbationsZhixi Cai, Kartik Kuckreja, Shreya Ghosh, Akanksha Chuchra, Muhammad Haris Khan, Usman Tariq, Tom Gedeon, and Abhinav DhallIn Proceedings of the 33rd ACM International Conference on Multimedia , 2025
The rapid surge of text-to-speech and face-voice reenactment models makes video fabrication easier and highly realistic. To encounter this problem, we require datasets that rich in type of generation methods and perturbation strategy which is usually common for online videos. To this end, we propose AV-Deepfake1M++, an extension of the AV-Deepfake1M having 2 million video clips with diversified manipulation strategy and audio-visual perturbation. This paper includes the description of data generation strategies along with benchmarking of AV-Deepfake1M++ using state-of-the-art methods. We believe that this dataset will play a pivotal role in facilitating research in Deepfake domain. Based on this dataset, we host the 2025 1M-Deepfakes Detection Challenge. The challenge details, dataset and evaluation scripts are available online under a research-only license at https://deepfakes1m.github.io/2025.
- Hier-SLAM: Scaling-up Semantics in SLAM with a Hierarchically Categorical Gaussian SplattingIn 2025 IEEE International Conference on Robotics and Automation (ICRA) , 2025
We propose Hi-SLAM, a semantic 3D Gaussian Splatting SLAM method featuring a novel hierarchical categorical representation, which enables accurate global 3D semantic mapping, scaling-up capability, and explicit semantic label prediction in the 3D world. The parameter usage in semantic SLAM systems increases significantly with the growing complexity of the environment, making it particularly challenging and costly for scene understanding. To address this problem, we introduce a novel hierarchical representation that encodes semantic information in a compact form into 3D Gaussian Splatting, leveraging the capabilities of large language models (LLMs). We further introduce a novel semantic loss designed to optimize hierarchical semantic information through both inter-level and cross-level optimization. Furthermore, we enhance the whole SLAM system, resulting in improved tracking and mapping performance. Our Hi-SLAM outperforms existing dense SLAM methods in both mapping and tracking accuracy, while achieving a 2x operation speed-up. Additionally, it exhibits competitive performance in rendering semantic segmentation in small synthetic scenes, with significantly reduced storage and training time requirements. Rendering FPS impressively reaches 2,000 with semantic information and 3,000 without it. Most notably, it showcases the capability of handling the complex real-world scene with more than 500 semantic classes, highlighting its valuable scaling-up capability.
- Multimodal Deepfake Generation and Detection: Challenges, Methods, and Future DirectionsAbhinav Dhall , Zhixi Cai, and Shreya GhoshIn Companion Proceedings of the 27th International Conference on Multimodal Interaction , 2025
The rapid advancement of generative AI has revolutionized the creation and manipulation of synthetic media across different use cases. However, this progress has also fuelled the rise of deepfakes; highly realistic audio, image, and video content generated without the consent of the individuals which has potential negative societal impact. These manipulated media artifacts can misrepresent people by making them appear to say or do things they never did, posing significant threats to privacy, trust, and public discourse.Deepfakes have become tools for disinformation, misinformation, online harassment, and even fraud, undermining systems such as facial recognition and video-based authentication (e.g., Know Your Customer aka KYC). As these manipulations grow more convincing, it becomes critical for platforms and systems to detect and mitigate them effectively.This tutorial will provide a comprehensive introduction to the generation, detection, and societal impact of deepfakes from a multimodal perspective. It will equip participants with foundational knowledge of generative techniques, explore cutting-edge deepfake detection methods, and offer hands-on experience with open-source tools. Attendees will also engage in discussion around ethical considerations and real-world deployment challenges, fostering a robust understanding of how to combat synthetic media threats in interactive systems.
- Explain Before You Answer: A Survey on Compositional Visual ReasoningFucai Ke, Joy Hsu , Zhixi Cai, Zixian Ma, Xin Zheng, Xindi Wu, Sukai Huang, Weiqing Wang, Pari Delir Haghighi, Gholamreza Haffari , and 3 more authorsarXiv preprint arXiv:2508.17298, 2025
Compositional visual reasoning has emerged as a key research frontier in multimodal AI, aiming to endow machines with the human-like ability to decompose visual scenes, ground intermediate concepts, and perform multi-step logical inference. While early surveys focus on monolithic vision-language models or general multimodal reasoning, a dedicated synthesis of the rapidly expanding compositional visual reasoning literature is still missing. We fill this gap with a comprehensive survey spanning 2023 to 2025 that systematically reviews 260+ papers from top venues (CVPR, ICCV, NeurIPS, ICML, ACL, etc.). We first formalize core definitions and describe why compositional approaches offer advantages in cognitive alignment, semantic fidelity, robustness, interpretability, and data efficiency. Next, we trace a five-stage paradigm shift: from prompt-enhanced language-centric pipelines, through tool-enhanced LLMs and tool-enhanced VLMs, to recently minted chain-of-thought reasoning and unified agentic VLMs, highlighting their architectural designs, strengths, and limitations. We then catalog 60+ benchmarks and corresponding metrics that probe compositional visual reasoning along dimensions such as grounding accuracy, chain-of-thought faithfulness, and high-resolution perception. Drawing on these analyses, we distill key insights, identify open challenges (e.g., limitations of LLM-based reasoning, hallucination, a bias toward deductive reasoning, scalable supervision, tool integration, and benchmark limitations), and outline future directions, including world-model integration, human-AI collaborative reasoning, and richer evaluation protocols. By offering a unified taxonomy, historical roadmap, and critical outlook, this survey aims to serve as a foundational reference and inspire the next generation of compositional visual reasoning research.
- MRAC 2025: 3rd International Workshop on Multimodal, Generative and Responsible Affective ComputingZheng Lian, Shreya Ghosh, Erik Cambria , Zhixi Cai, Guoying Zhao, Abhinav Dhall, Björn W. Schuller, Roland Goecke, Jianhua Tao, and Tom GedeonIn Proceedings of the 33rd ACM International Conference on Multimedia , 2025
Multimodal, generative, and responsible affective computing aims to enhance people’s lives. In recent years, the AI revolution has already begun to impact daily life, with virtual assistants being deployed across various sectors such as healthcare, banking, transportation, and education. It is clear that, in the near future, humans may interact with AI-powered systems as much or maybe even more than direct human-to-human interactions. Affective computing has numerous applications, including innovative approaches to forecasting and preventing anxiety, stress, and mental health issues; enhancing robotic empathy; assisting individuals with communication, behavior, and emotion regulation challenges; and promoting awareness of health and well-being. Many of these applications require enhanced control and protection of sensitive, private, and personal data. Therefore, it is crucial to further develop the creation, evaluation, and deployment of emotionally intelligent systems that are both responsive and responsible. Additionally, improving the accuracy and interpretability of emotion prediction results can significantly enhance the application of this technology in the downstream tasks mentioned above. MRAC’25 is the continuation of MRAC’23 and MRAC’24. Through this workshop, we aim to bring together researchers to discuss the potential and development of affective computing.
- DWIM: Towards Tool-aware Visual Reasoning via Discrepancy-aware Workflow Generation & Instruct-Masking TuningFucai Ke, Vijay Kumar B G, Xingjian Leng , Zhixi Cai, Zaid Khan, Weiqing Wang, Pari Delir Haghighi, Hamid Rezatofighi, and Manmohan ChandrakerIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , 2025
Visual reasoning (VR), which is crucial in many fields for enabling human-like visual understanding, remains highly challenging. Recently, compositional visual reasoning approaches, which leverage the reasoning abilities of large language models (LLMs) with integrated tools to solve problems, have shown promise as more effective strategies than end-to-end VR methods. However, these approaches face limitations, as frozen LLMs lack tool awareness in VR, leading to performance bottlenecks. While leveraging LLMs for reasoning is widely used in other domains, they are not directly applicable to VR due to limited training data, imperfect tools that introduce errors and reduce data collection efficiency in VR, and challenging in fine-tuning on noisy workflows. To address these challenges, we propose DWIM: i) Discrepancy-aware training Workflow generation, which assesses tool usage and extracts more viable workflows for training; and ii) Instruct-Masking fine-tuning, which guides the model to only clone effective actions, enabling the generation of more practical solutions. Our experiments demonstrate that DWIM achieves state-of-the-art performance across various VR tasks, exhibiting strong generalization on multiple widely-used datasets.








2024
- AV-Deepfake1M: A Large-Scale LLM-Driven Audio-Visual Deepfake DatasetZhixi Cai, Shreya Ghosh, Aman Pankaj Adatia, Munawar Hayat, Abhinav Dhall, Tom Gedeon, and Kalin StefanovIn Proceedings of the 32nd ACM International Conference on Multimedia , 2024
The detection and localization of highly realistic deepfake audio-visual content are challenging even for the most advanced state-of-the-art methods. While most of the research efforts in this domain are focused on detecting high-quality deepfake images and videos, only a few works address the problem of the localization of small segments of audio-visual manipulations embedded in real videos. In this research, we emulate the process of such content generation and propose the AV-Deepfake1M dataset. The dataset contains content-driven (i) video manipulations, (ii) audio manipulations, and (iii) audio-visual manipulations for more than 2K subjects resulting in a total of more than 1M videos. The paper provides a thorough description of the proposed data generation pipeline accompanied by a rigorous analysis of the quality of the generated data. The comprehensive benchmark of the proposed dataset utilizing state-of-the-art deepfake detection and localization methods indicates a significant drop in performance compared to previous datasets. The proposed dataset will play a vital role in building the next-generation deepfake localization methods. The dataset and associated code are available at https://github.com/ControlNet/AV-Deepfake1M.
- 1M-Deepfakes Detection ChallengeZhixi Cai, Abhinav Dhall, Shreya Ghosh, Munawar Hayat, Dimitrios Kollias, Kalin Stefanov, and Usman TariqIn Proceedings of the 32nd ACM International Conference on Multimedia , 2024
The detection and localization of deepfake content, particularly when small fake segments are seamlessly mixed with real videos, remains a significant challenge in the field of digital media security. Based on the recently released AV-Deepfake1M dataset, which contains more than 1 million manipulated videos across more than 2,000 subjects, we introduce the 1M-Deepfakes Detection Challenge. This challenge is designed to engage the research community in developing advanced methods for detecting and localizing deepfake manipulations within the large-scale high-realistic audio-visual dataset. The participants can access the AV-Deepfake1M dataset and are required to submit their inference results for evaluation across the metrics for detection or localization tasks. The methodologies developed through the challenge will contribute to the development of next-generation deepfake detection and localization systems. Evaluation scripts, baseline models, and accompanying code will be available on https://github.com/ControlNet/AV-Deepfake1M.
- Content-Driven Multimodal Deepfake Generation and Temporal LocalizationZhixi CaiMonash University , 2024
This thesis investigates the challenges and advances in detecting sophisticated video manipulations named content-driven deepfakes, where slight, strategic changes can drastically alter the video’s meaning. Focusing on the content-driven deepfakes not well-addressed by current detection methods, this research introduces new datasets and detection approaches for precisely localizing these manipulations. This thesis contributes valuable tools and insights for addressing deepfake threats, highlighting the importance of reliable detection in maintaining media integrity and security.
- HYDRA: A Hyper Agent for Dynamic Compositional Visual ReasoningFucai Ke* , Zhixi Cai*, Simindokht Jahangard*, Weiqing Wang, Pari Delir Haghighi, and Hamid RezatofighiIn European Conference on Computer Vision , 2024
Recent advances in visual reasoning (VR), particularly with the aid of Large Vision-Language Models (VLMs), show promise but require access to large-scale datasets and face challenges such as high computational costs and limited generalization capabilities. Compositional visual reasoning approaches have emerged as effective strategies; however, they heavily rely on the commonsense knowledge encoded in Large Language Models (LLMs) to perform planning, reasoning, or both, without considering the effect of their decisions on the visual reasoning process, which can lead to errors or failed procedures. To address these challenges, we introduce HYDRA, a multi-stage dynamic compositional visual reasoning framework designed for reliable and incrementally progressive general reasoning. HYDRA integrates three essential modules: a planner, a Reinforcement Learning (RL) agent serving as a cognitive controller, and a reasoner. The planner and reasoner modules utilize an LLM to generate instruction samples and executable code from the selected instruction, respectively, while the RL agent dynamically interacts with these modules, making high-level decisions on selection of the best instruction sample given information from the historical state stored through a feedback loop. This adaptable design enables HYDRA to adjust its actions based on previous feedback received during the reasoning process, leading to more reliable reasoning outputs and ultimately enhancing its overall effectiveness. Our framework demonstrates state-of-the-art performance in various VR tasks on four different widely-used datasets.
- Emolysis: A Multimodal Open-Source Group Emotion Analysis and Visualization ToolkitShreya Ghosh* , Zhixi Cai*, Parul Gupta, Garima Sharma, Abhinav Dhall, Munawar Hayat, and Tom GedeonIn 12th International Conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW) , 2024
Automatic group emotion recognition plays an important role in understanding complex human-human interaction. This paper introduces, Emolysis, a standalone open-source toolkit for real-time multimodal group emotion recognition and visualization. Given any input video, Emolysis processes nearly real-time synchronized multimodal input and maps it to group level emotion, valence and arousal. Additionally, the toolkit supports major mobile and desktop platforms (Android, iOS, Windows). The Emolysis platform also comes with an intuitive graphical user interface that allows users to select different modalities and target persons for more fine grained emotion analysis. Emolysis is freely available for academic research, and encourages application developers to extend it to application specific environments on top of the existing system. We believe that the extension mechanism is quite straightforward. Our code and models are available at https://github.com/ControlNet/emolysis.
- JRDB-Social: A Multifaceted Robotic Dataset for Understanding of Context and Dynamics of Human Interactions Within Social GroupsSimindokht Jahangard , Zhixi Cai, Shiki Wen, and Hamid RezatofighiIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2024
Understanding human social behaviour is crucial in computer vision and robotics. Micro-level observations like individual actions fall short necessitating a comprehensive approach that considers individual behaviour intra-group dynamics and social group levels for a thorough understanding. To address dataset limitations this paper introduces JRDB-Social an extension of JRDB. Designed to fill gaps in human understanding across diverse indoor and outdoor social contexts JRDB-Social provides annotations at three levels: individual attributes intra-group interactions and social group context. This dataset aims to enhance our grasp of human social dynamics for robotic applications. Utilizing the recent cutting-edge multi-modal large language models we evaluated our benchmark to explore their capacity to decipher social human behaviour.
- MRAC Track 1: 2nd Workshop on Multimodal, Generative and Responsible Affective ComputingIn Proceedings of the 2nd International Workshop on Multimodal and Responsible Affective Computing , 2024
With the rapid advancements in multimodal generative technology, Affective Computing research has provoked discussion about the potential consequences of AI systems equipped with emotional intelligence. Affective Computing involves the design, evaluation, and implementation of Emotion AI and related technologies aimed at improving people’s lives. Designing a computational model in affective computing requires vast amounts of multimodal data, including RGB images, video, audio, text, and physiological signals. Moreover, Affective Computing research is deeply engaged with ethical considerations at various stages’from training emotionally intelligent models on large-scale human data to deploying these models in specific applications. Fundamentally, the development of any AI system must prioritize its impact on humans, aiming to augment and enhance human abilities rather than replace them, while drawing inspiration from human intelligence in a safe and responsible manner. The MRAC 2024 Track 1 workshop seeks to extend these principles from controlled, small-scale lab environments to real-world, large-scale contexts, emphasizing responsible development. The workshop also aims to highlight the potential implications of generative technology, along with the ethical consequences of its use, to researchers and industry professionals. To the best of our knowledge, this is the first workshop series to comprehensively address the full spectrum of multimodal, generative affective computing from a responsible AI perspective, and this is the second iteration of this workshop. Webpage: https://react-ws.github.io/2024/







2023
- MARLIN: Masked Autoencoder for facial video Representation LearnINgZhixi Cai, Shreya Ghosh, Kalin Stefanov, Abhinav Dhall, Jianfei Cai, Hamid Rezatofighi, Reza Haffari, and Munawar HayatIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2023
This paper proposes a self-supervised approach to learn universal facial representations from videos, that can transfer across a variety of facial analysis tasks such as Facial Attribute Recognition (FAR), Facial Expression Recognition (FER), DeepFake Detection (DFD), and Lip Synchronization (LS). Our proposed framework, named MARLIN, is a facial video masked autoencoder, that learns highly robust and generic facial embeddings from abundantly available non-annotated web crawled facial videos. As a challenging auxiliary task, MARLIN reconstructs the spatio-temporal details of the face from the densely masked facial regions which mainly include eyes, nose, mouth, lips, and skin to capture local and global aspects that in turn help in encoding generic and transferable features. Through a variety of experiments on diverse downstream tasks, we demonstrate MARLIN to be an excellent facial video encoder as well as feature extractor, that performs consistently well across a variety of downstream tasks including FAR (1.13% gain over supervised benchmark), FER (2.64% gain over unsupervised benchmark), DFD (1.86% gain over unsupervised benchmark), LS (29.36% gain for Frechet Inception Distance), and even in low data regime. Our code and models are available at https://github.com/ControlNet/MARLIN.
- Glitch in the Matrix: A Large Scale Benchmark for Content Driven Audio-Visual Forgery Detection and LocalizationComputer Vision and Image Understanding, 2023
Most deepfake detection methods focus on detecting spatial and/or spatio-temporal changes in facial attributes and are centered around the binary classification task of detecting whether a video is real or fake. This is because available benchmark datasets contain mostly visual-only modifications present in the entirety of the video. However, a sophisticated deepfake may include small segments of audio or audio-visual manipulations that can completely change the meaning of the video content. To addresses this gap, we propose and benchmark a new dataset, Localized Audio Visual DeepFake (LAV-DF), consisting of strategic content-driven audio, visual and audio-visual manipulations. The proposed baseline method, Boundary Aware Temporal Forgery Detection (BA-TFD), is a 3D Convolutional Neural Network-based architecture which effectively captures multimodal manipulations. We further improve (i.e. BA-TFD) the baseline method by replacing the backbone with a Multiscale Vision Transformer and guide the training process with contrastive, frame classification, boundary matching and multimodal boundary matching loss functions. The quantitative analysis demonstrates the superiority of BA-TFD on temporal forgery localization and deepfake detection tasks using several benchmark datasets including our newly proposed dataset. The dataset, models and code are available at https://github.com/ControlNet/LAV-DF.
- Pavlok-Nudge: A Feedback Mechanism for Atomic Behaviour Modification with Snoring UsecaseShreya Ghosh, Rakibul Hasan, Pradyumna Agrawal , Zhixi Cai, Susannah Soon, Abhinav Dhall, and Tom GedeonarXiv preprint arXiv:2305.06110, 2023
This paper proposes a feedback mechanism to ’break bad habits’ using the Pavlok device. Pavlok utilises beeps, vibration and shocks as a mode of aversion technique to help individuals with behaviour modification. While the device can be useful in certain periodic daily life situations, like alarms and exercise notifications, the device relies on manual operations that limit its usage. To this end, we design a user interface to generate an automatic feedback mechanism that integrates Pavlok and a deep learning based model to detect certain behaviours via an integrated user interface i.e. mobile or desktop application. Our proposed solution is implemented and verified in the context of snoring, which first detects audio from the environment following a prediction of whether the audio content is a snore or not. Based on the prediction of the deep learning model, we use Pavlok to alert users for preventive measures. We believe that this simple solution can help people to change their atomic habits, which may lead to long-term benefits.



2022
- Do You Really Mean That? Content Driven Audio-Visual Deepfake Dataset and Multimodal Method for Temporal Forgery LocalizationIn 2022 International Conference on Digital Image Computing: Techniques and Applications (DICTA) , 2022
Due to its high societal impact, deepfake detection is getting active attention in the computer vision community. Most deepfake detection methods rely on identity, facial attributes, and adversarial perturbation-based spatio-temporal modifications at the whole video or random locations while keeping the meaning of the content intact. However, a sophisticated deepfake may contain only a small segment of video/audio manipulation, through which the meaning of the content can be, for example, completely inverted from a sentiment perspective. We introduce a content-driven audio-visual deepfake dataset, termed Localized Audio Visual DeepFake (LAV-DF), explicitly designed for the task of learning temporal forgery localization. Specifically, the content-driven audio-visual manipulations are performed strategically to change the sentiment polarity of the whole video. Our baseline method for benchmarking the proposed dataset is a 3DCNN model, termed as Boundary Aware Temporal Forgery Detection (BA-TFD), which is guided via contrastive, boundary matching, and frame classification loss functions. Our extensive quantitative and qualitative analysis demonstrates the proposed method’s strong performance for temporal forgery localization and deepfake detection tasks.
